
Contents
Artificial intelligence (A.I.) describes a variety of techniques that allow a computer program to train on and learn from data to perform tasks such as detecting objects in a photo, driving a vehicle, or identifying the main topics of a text. In this blog post, we will introduce you to Starmind’s A.I. research in general, while also providing some in-depth information for experts and hope to provide a fascinating insight into some of our work.
No Starmind Without A.I. Technology
A.I. technology, in particular machine learning, has been at the core of Starmind since its early days. Starmind learns the expertise of a person from the interactions with topics. To model those interactions over time, we need to identify the importance, generality, and context of the topic. This complex task can neither be done manually nor solved with a purely rule based system, which made us realize we need a specialized machine learning system that can learn who is an expert on which topics.
Over time, our system has evolved from some basic algorithms to a highly advanced machine learning pipeline that uses techniques from online graph learning, natural language processing (NLP), word and sentence embeddings, deep learning and other fields. The type of data our pipeline deals with also diversified over time: in the beginning, only question and answer data from Starmind’s Q&A application was processed. Now, we are also able to process many other textual data types such as chat messages, support tickets, project descriptions and calendar entries. All these data types get processed and weighted in importance to provide a person’s comprehensive expertise profile.
At the Forefront of the A.I. Evolution
A.I. has been one of the fastest evolving areas of science and technology for some years now. As an A.I. company, Starmind not only has to leverage state-of-the-art technologies but also drive the development of new systems to improve its product and customer experience. For this, we keep track of relevant new A.I. developments and published papers, ranging from improvements of techniques we already use to disruptive novelties that may completely reshape how we do things.
When reading new A.I. research papers, just looking at the reported results, i.e. scores on some task, is not enough to assess the usefulness of a new model or technique for us. A model may perform very well on some public benchmarking dataset used in a paper, while performing badly on real customer data. A common cause of this discrepancy is the amount of available data. A machine learning algorithm often performs better the more data it can train on. Novel neural network and transformer models for NLP tasks are trained on huge datasets with billions of words. In the real world, though, the amount of data is often far more limited. At Starmind, we have the interesting situation that, on the one hand, for some clients we do not have a lot of data to work with, while, on the other hand, for some customers we process a large amount of data. Our system has to provide useful results in both scenarios. This is reflected in our benchmarking process for new methods, which assesses whether a new model performs well in all cases.
Another challenge is the way language is used by different clients, i.e. within different companies. A word can have a different meaning depending on the context in which it is embedded, but also from the professional scope of the people using it. The generality of a word, not only its frequency in the language but also within an organization, can vary a lot. For example, the word ‘frontend’ is a very general term in a web design company, however, in an insurance company, it is a rather specific term. Any model of expertise has to take the generality of a topic into account.
Starmind’s Contributions to A.I. Technology
We do not only rely on others to develop or improve machine learning techniques, but also conduct A.I. research ourselves here at Starmind. The following three examples of active research projects illustrate Starmind’s contributions to machine learning and A.I.
Part-of-Speech Tagging
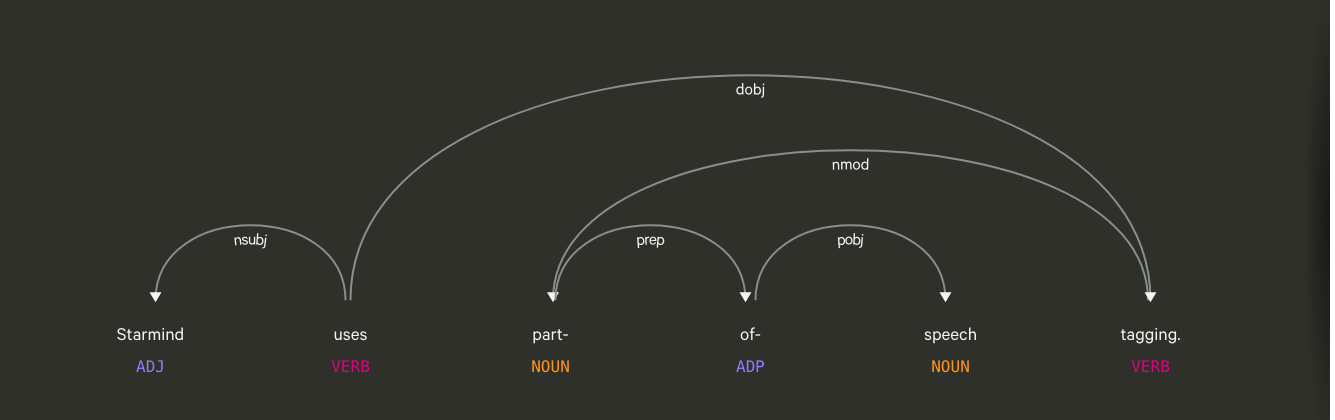 Part-of-speech tagging and dependency parsing using spaCy.
Part-of-speech tagging and dependency parsing using spaCy.
One of our main challenges is to correctly identify words and phrases that are relevant topics in a specific document. For this task, we use part-of-speech tagging and dependency parsing. Publicly available libraries, e.g. spacy, are becoming more powerful and multilingual, yet they still provide results that need some intelligent tweaking to reach the quality level we want. The libraries provide us with information on how words within a sentence are connected, and what type of word (e.g. adjective, noun, etc.) they are. Our intelligent pipeline can then decide whether a single noun or maybe a combination of nouns and adjectives should be extracted as a topic. In our research, this component in constantly tweaked, but we also investigate completely new ways to extract keyphrases, for example with recurrent neural networks (RNNs) as was shown in the CopyRNN paper.
Document and Sentence Embedding
We employ sentence embeddings, amongst other use cases, to quickly find similar questions to a new question. We have had very good results with an algorithm based on Reflective Random Indexing, a relatively old and simple embedding method. Newer methods based on pretrained models like Word2Vec or StarSpace were not able to train as quickly on our data. Continuously benchmarking new methods that appeared, we also tested transformer based models such as BERT and ELMO. They gave accurate results, but did not perform efficiently enough for us. The embedding vectors generated by BERT and ELMO are not suitable for the cosine distance metric. Consequently, the computational complexity of finding the nearest neighbours increases significantly.
The Universal Sentence Encoding (USE), which is also based transformers, turned out to be more suitable for our needs, especially since it's now possible to use USE on multilingual data. USE, in conjunction with several additional components developed at Starmind, allows us to provide good search results for our customers. Nevertheless, our research also continues to look into the development of a custom transformer based model that works better on our data.
Fundamental Research at Starmind
 ETH Zurich Main Building © ETH Zürich / Gian Marco Castelberg
ETH Zurich Main Building © ETH Zürich / Gian Marco Castelberg
Starmind collaborates with ETH Zurich and the Institute of Neuroinformatics in a joint industrial Ph.D. on fundamental research. The program also creates a tight connection to the university to exchange knowledge and attract talents. As a result, ETH students have the opportunity to develop their M.Sc. semester project at Starmind. For example develop more intelligent and selective ways of doing backpropagation through time (BPTT) to train RNNs on an NLP task.
One of the fundamental research projects is the development of biologically inspired neural networks for sequence modeling. Here, Joachim Ott creates new models of RNNs that overcome some limitations of currently used RNNs and transformers. Although RNNs and transformers are the best models for many tasks involving sequential data at the moment, their limitations are numerous. To name a few: catastrophic forgetting, which means a model loses all knowledge if trained on a new task. They need a lot of training data, and they require large computational resources, especially transformers. Biological neural networks, e.g. brains, do not have these limitations: they are very power efficient, even a human brain consumes only ~10 watt. They can transfer knowledge to new tasks, and a single sample is sometimes enough to understand a new concept.
The goal of our research is to get inspiration from biology to improve artificial neural networks to be closer to brains in these important aspects. We do not want to simulate real neurons as precise as possible, for example with neuro physical models or spiking neural networks. We rather want to find the computational concepts of biological neural networks that are responsible for the aforementioned superiority.
As a first step, we need to compare the key differences of current models for sequential data like RNNs to biological neural networks. RNNs require a forward and backward pass, the credit assignment via BPTT requires symmetric weights for both computational paths, and is non-local since we have to know the state of all neurons to calculate the gradient for a given neuron, and non-causal because we go backwards in time. Transformers are even further away from biology, since they do not have a concept of time. In transformer training, the position of a sequence token is a feature encoded with a list of sinusoidal coordinates of different frequency.
At the moment, we investigate local self-supervised learning, which is new and more precise terminology for ‘unsupervised learning’, in combination with multi-component weights with the goal of finding a more powerful representation for sequences and overcome catastrophic forgetting.
We are Team Human
 We are Team Human!
We are Team Human!
Research at Starmind helps us to continuously improve the experience for our clients by staying up-to-date with current methods and latest algorithms in A.I. We are interested in bringing A.I. technology to the next frontier and develop new A.I. systems by doing research on all levels - from small improvements to concrete fundamental research. A.I. augments our understanding of humans, particularly their talents and skills, and plays a crucial role in realizing our vision: making collective human intelligence accessible to everybody.


